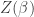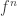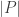An interesting result that demonstrates, among other things, the ubiquity of ![\pi]() in mathematics is that the probability that two random positive integers are relatively prime is
in mathematics is that the probability that two random positive integers are relatively prime is ![\frac{6}{\pi^2}]() . A more revealing way to write this number is
. A more revealing way to write this number is ![\frac{1}{\zeta(2)}]() , where
, where
![\displaystyle \zeta(s) = \sum_{n \ge 1} \frac{1}{n^s}]()
is the Riemann zeta function. A few weeks ago this result came up on math.SE in the following form: if you are standing at the origin in ![\mathbb{R}^2]() and there is an infinitely thin tree placed at every integer lattice point, then
and there is an infinitely thin tree placed at every integer lattice point, then ![\frac{6}{\pi^2}]() is the proportion of the lattice points that you can see. In this post I’d like to explain why this “should” be true. This will give me a chance to blog about some material from another math.SE answer of mine which I’ve been meaning to get to, and along the way we’ll reach several other interesting destinations.
is the proportion of the lattice points that you can see. In this post I’d like to explain why this “should” be true. This will give me a chance to blog about some material from another math.SE answer of mine which I’ve been meaning to get to, and along the way we’ll reach several other interesting destinations.
Densities and measures
First of all, what do we mean by a “random” integer? It’s not hard to see that there is no uniform probability distribution on the positive integers. The strongest statement that is meant when somebody says that a positive integer has a probability of ![p]() of being in some subset
of being in some subset ![S \subseteq \mathbb{N}]() is that the natural density
is that the natural density
![\displaystyle \lim_{n \to \infty} \frac{ | \{ 1, 2, ... n \} \cap S |}{n}]()
is equal to ![p]() . For example, by this definition the probability that a positive integer is divisible by
. For example, by this definition the probability that a positive integer is divisible by ![k]() is
is ![\frac{1}{k}]() , as one would expect. Natural density, however, has drawbacks: it is not defined for every subset of
, as one would expect. Natural density, however, has drawbacks: it is not defined for every subset of ![\mathbb{N}]() , and it does not form a probability measure in the measure-theoretic sense. In particular, it’s not countably additive, since each positive integer has measure
, and it does not form a probability measure in the measure-theoretic sense. In particular, it’s not countably additive, since each positive integer has measure ![0]() but their union has measure
but their union has measure ![1]() .
.
If we want an honest probability measure on ![\mathbb{N}]() , we need to choose a sequence of non-negative real numbers
, we need to choose a sequence of non-negative real numbers ![a_n, n \in \mathbb{N}]() such that
such that ![\sum a_n = 1]() . Since we’re trying to answer a number-theoretic question about relatively prime integers, we should pick the
. Since we’re trying to answer a number-theoretic question about relatively prime integers, we should pick the ![a_n]() to have nice number-theoretic properties. One property that’s natural to ask for, as above, is that the probability that an integer is divisible by
to have nice number-theoretic properties. One property that’s natural to ask for, as above, is that the probability that an integer is divisible by ![p]() should be
should be ![\frac{1}{p}]() for any positive integer
for any positive integer ![p]() . In other words, we want
. In other words, we want
![\displaystyle \sum_{k=1}^{\infty} a_{pk} = \frac{1}{p}]()
for all ![p \ge 1]() . This implies, among other things, that the events that an integer is divisible by one of two relatively prime positive integers are independent.
. This implies, among other things, that the events that an integer is divisible by one of two relatively prime positive integers are independent.
Unfortunately, this is impossible. For any fixed positive integer ![n]() , it’s clear that
, it’s clear that ![a_n]() is at most the probability that a positive integer is not divisible by
is at most the probability that a positive integer is not divisible by ![p]() for any prime
for any prime ![p \nmid n]() . The probability that a positive integer is not divisible by
. The probability that a positive integer is not divisible by ![p]() is
is ![1 - \frac{1}{p}]() , and since these events are independent, the probability that a positive integer is not divisible by the primes not dividing
, and since these events are independent, the probability that a positive integer is not divisible by the primes not dividing ![n]() is
is
![\displaystyle \prod_{p \nmid n} \left( 1 - \frac{1}{p} \right)]()
which diverges to zero, so ![a_n = 0]() ; contradiction.
; contradiction.
Here’s one explanation for why this condition can’t work which I think is revealing. One way to justify requiring that the probability that a positive integer is divisible by ![p]() is
is ![\frac{1}{p}]() is that this is true for all finite quotients of
is that this is true for all finite quotients of ![\mathbb{Z}]() ; that is, in
; that is, in ![\mathbb{Z}/n\mathbb{Z}]() it’s true that for all positive integers
it’s true that for all positive integers ![m | n]() , exactly
, exactly ![\frac{1}{m}]() of the residues are congruent to
of the residues are congruent to ![0 \bmod m]() . In other words, when we imposed the above requirement, we were secretly looking for a probability distribution compatible with the counting measure on the finite quotients of
. In other words, when we imposed the above requirement, we were secretly looking for a probability distribution compatible with the counting measure on the finite quotients of ![\mathbb{Z}]() . Whenever you want to talk about the finite quotients of a group
. Whenever you want to talk about the finite quotients of a group ![G]() , there’s a universal object that lets you talk about all of them at once: the profinite completion
, there’s a universal object that lets you talk about all of them at once: the profinite completion ![\hat{G}]() , defined as the limit of the diagram of the finite quotients of
, defined as the limit of the diagram of the finite quotients of ![G]() equipped with the obvious morphisms (that is, if
equipped with the obvious morphisms (that is, if ![N, M]() are two subgroups of finite index such that
are two subgroups of finite index such that ![N \subset M]() , then there is an obvious morphism
, then there is an obvious morphism ![G/M \to G/N]() ). The profinite completion
). The profinite completion ![\hat{G}]() comes equipped with a natural map
comes equipped with a natural map ![G \to \hat{G}]() which is not always injective and with natural projections
which is not always injective and with natural projections ![\hat{G} \to G/M]() for every finite quotient of
for every finite quotient of ![G]() . It also comes with the initial topology making these projections continuous, and with this topology it is Hausdorff, compact, and totally disconnected. In addition, the image of
. It also comes with the initial topology making these projections continuous, and with this topology it is Hausdorff, compact, and totally disconnected. In addition, the image of ![G]() is dense.
is dense.
Example. The profinite completion of ![\mathbb{Z}]() is a gadget
is a gadget ![\hat{\mathbb{Z}}]() called the profinite integers. By the Chinese Remainder Theorem, it is isomorphic to the direct product
called the profinite integers. By the Chinese Remainder Theorem, it is isomorphic to the direct product ![\prod_p \mathbb{Z}_p]() . Profinite groups often appear as Galois groups, and in this case
. Profinite groups often appear as Galois groups, and in this case ![\hat{\mathbb{Z}}]() naturally occurs as the absolute Galois group of a finite field.
naturally occurs as the absolute Galois group of a finite field.
Example. The profinite completion of ![\mathbb{Q}]() is the trivial group because
is the trivial group because ![\mathbb{Q}]() has no finite quotients! This shows that the natural map from a group into its profinite completion need not be injective.
has no finite quotients! This shows that the natural map from a group into its profinite completion need not be injective.
Since ![\hat{G}]() is compact Hausdorff, it comes equipped with a canonical (say, left) Haar measure (the one which assigns the entire group measure
is compact Hausdorff, it comes equipped with a canonical (say, left) Haar measure (the one which assigns the entire group measure ![1]() ). This is important because it describes a probability measure on
). This is important because it describes a probability measure on ![\hat{G}]() . For profinite groups the Haar measure is particularly easy to describe. Any Borel measure on a topological space is determined by what it does to a basis of open sets, and for profinite groups
. For profinite groups the Haar measure is particularly easy to describe. Any Borel measure on a topological space is determined by what it does to a basis of open sets, and for profinite groups ![\hat{G}]() such a basis is given by the partitions determined by every projection
such a basis is given by the partitions determined by every projection ![\hat{G} \to G/N]() . The kernel of such a morphism is a subgroup of finite index, and by invariance all of its cosets must have the same measure as it, so they must all have measure
. The kernel of such a morphism is a subgroup of finite index, and by invariance all of its cosets must have the same measure as it, so they must all have measure ![\frac{1}{|G/N|}]() . In particular, the (normalized) Haar measure on
. In particular, the (normalized) Haar measure on ![\hat{\mathbb{Z}}]() is the unique one which assigns measure
is the unique one which assigns measure ![\frac{1}{n}]() to the kernel of the projection
to the kernel of the projection ![\hat{\mathbb{Z}} \to \mathbb{Z}/n\mathbb{Z}]() .
.
This is precisely the property we wanted from a probability distribution on ![\mathbb{Z}]() . But now the bitter truth hits us: in
. But now the bitter truth hits us: in ![\hat{\mathbb{Z}}]() , the subgroup
, the subgroup ![\mathbb{Z}]() has measure zero! One way to see this is that the identity is in the kernel of every projection, so it has measure less than
has measure zero! One way to see this is that the identity is in the kernel of every projection, so it has measure less than ![\frac{1}{n}]() for every
for every ![n]() , hence measure zero. And by invariance, every element of
, hence measure zero. And by invariance, every element of ![\hat{\mathbb{Z}}]() has measure zero (in other words, there are no atoms), hence
has measure zero (in other words, there are no atoms), hence ![\mathbb{Z}]() also has measure zero. One can also repeat the first proof given above in this context, but the point is that we are free to use invariance here because it was already guaranteed by the requirement that the measure be compatible with projections to the finite quotients. So we are totally defeated by this requirement, which is too strong.
also has measure zero. One can also repeat the first proof given above in this context, but the point is that we are free to use invariance here because it was already guaranteed by the requirement that the measure be compatible with projections to the finite quotients. So we are totally defeated by this requirement, which is too strong.
(On the other hand, if we are ever in a situation where we want to pick random integers, we should perhaps think about picking random profinite integers instead because we now know there is a perfectly reasonable way to do this.)
The zeta distributions
What now? Well, the Chinese Remainder Theorem suggests that it is still natural to require that the events of being divisible by two relatively prime integers should be independent. This is equivalent to choosing the different exponents in the prime factorization ![n = p_1^{e_1} p_2^{e_2} ...]() independently. So how do we choose the exponent of a particular prime
independently. So how do we choose the exponent of a particular prime ![p]() ?
?
To answer this restricted question, the relevant quotients of ![\mathbb{Z}]() this time are the finite quotients
this time are the finite quotients ![\mathbb{Z}/p^k\mathbb{Z}]() . In such a finite quotient the probability of not being divisible by
. In such a finite quotient the probability of not being divisible by ![p]() is
is ![\frac{p-1}{p}]() , the probability of being divisible by
, the probability of being divisible by ![p]() (but not by
(but not by ![p^2]() ) is
) is ![\frac{p-1}{p^2}]() , the probability of being divisible by
, the probability of being divisible by ![p^2]() (but not by
(but not by ![p^3]() ) is
) is ![\frac{p-1}{p^3}]() , and so forth. This geometric behavior extends even to the limit of these quotients, which is the
, and so forth. This geometric behavior extends even to the limit of these quotients, which is the ![p]() -adic integers
-adic integers ![\mathbb{Z}_p]() . The
. The ![p]() -adic integers also have a canonical normalized Haar measure, and again because of compatibility with the finite quotients
-adic integers also have a canonical normalized Haar measure, and again because of compatibility with the finite quotients ![\mathbb{Z}_p \to \mathbb{Z}/p^k\mathbb{Z}]() the measure of the kernel (the elements divisible by
the measure of the kernel (the elements divisible by ![p^k]() ) is
) is ![\frac{1}{p^k}]() , which duplicates the above behavior. So it is tempting to make the exponent of
, which duplicates the above behavior. So it is tempting to make the exponent of ![p]() be equal to
be equal to ![e]() with probability
with probability ![\frac{p-1}{p^e}]() .
.
But since the profinite integers ![\hat{\mathbb{Z}}]() are just the direct product of the
are just the direct product of the ![\mathbb{Z}_p]() , we are just repeating the same argument as above, but locally, so we know this can’t work. (To see this explicitly, once again we can compute the measure of
, we are just repeating the same argument as above, but locally, so we know this can’t work. (To see this explicitly, once again we can compute the measure of ![1]() .) However, it is still natural to use a geometric distribution, for example because it maximizes entropy given a mean: see Keith Conrad’s excellent exposition on the subject. So let’s make the exponent of
.) However, it is still natural to use a geometric distribution, for example because it maximizes entropy given a mean: see Keith Conrad’s excellent exposition on the subject. So let’s make the exponent of ![p]() equal to
equal to ![e]() with probability
with probability ![(1 - r_p) r_p^e]() for some constant
for some constant ![r_p > 0]() .
.
With this choice, the measure of a positive integer ![n = p_1^{e_1} ... p_k^{e_k}]() is now equal to
is now equal to
![\displaystyle a_n = r_{p_1}^{e_1} ... r_{p_n}^{e_n} \prod_p (1 - r_p)]()
so we see that the product ![\prod_p (1 - r_p)]() needs to converge in order for this measure to make sense. Other than that requirement,mhow do we pin down a nice choice of the constants
needs to converge in order for this measure to make sense. Other than that requirement,mhow do we pin down a nice choice of the constants ![r_p]() ?
?
One additional requirement we can impose is that the measure of a positive integer is monotonically decreasing. It turns out (and I will leave this as a nice exercise) that this is possible if and only if ![r_p = p^{-s}]() for some positive real constant
for some positive real constant ![s]() . Since
. Since ![\prod_p (1 - r_p)]() also needs to converge, it turns out (again, exercise) that this is possible if and only if
also needs to converge, it turns out (again, exercise) that this is possible if and only if ![s]() is greater than
is greater than ![1]() . This then gives
. This then gives
![\displaystyle a_n = \frac{1}{\zeta(s)} \left( \frac{1}{n^s} \right)]()
where ![\zeta(s)]() is the zeta function! (This is one way to flesh out the tantalizing statement made by Rota which I quoted in this old blog post, although I don’t know if it’s the precise result that Rota had in mind.) This distribution is the zeta distribution on
is the zeta function! (This is one way to flesh out the tantalizing statement made by Rota which I quoted in this old blog post, although I don’t know if it’s the precise result that Rota had in mind.) This distribution is the zeta distribution on ![\mathbb{N}]() with parameter
with parameter ![s]() .
.
One way to think about the zeta distribution is as the probability distribution coming from viewing ![\zeta(s)]() as the partition function of a certain statistical-mechanical system, the Riemann gas, whose states are the positive integers
as the partition function of a certain statistical-mechanical system, the Riemann gas, whose states are the positive integers ![n]() and whose energies are their logarithms
and whose energies are their logarithms ![\log n]() . As with many other cool connections in mathematics, this was discussed by John Baez, who has links to more information, such as this wonderful page. One can think of a positive integer
. As with many other cool connections in mathematics, this was discussed by John Baez, who has links to more information, such as this wonderful page. One can think of a positive integer ![n]() as describing a multiset of fictitious particles called “primons,” where each primon
as describing a multiset of fictitious particles called “primons,” where each primon ![p]() occurs with multiplicity the corresponding exponent in the prime factorization of
occurs with multiplicity the corresponding exponent in the prime factorization of ![n]() and energy
and energy ![\log p]() . So
. So ![\log n]() is the sum of the energies of all the primons in the state corresponding to
is the sum of the energies of all the primons in the state corresponding to ![n]() .
.
The parameter ![s]() corresponds to inverse temperature, and as
corresponds to inverse temperature, and as ![s \to 1^{+}]() the partition function diverges, which corresponds to the Hagedorn temperature of the system. In this limit each state becomes closer to being equally likely; in other words, we are getting closer and closer to a uniform probability distribution on
the partition function diverges, which corresponds to the Hagedorn temperature of the system. In this limit each state becomes closer to being equally likely; in other words, we are getting closer and closer to a uniform probability distribution on ![\mathbb{N}]() , if such a thing existed.
, if such a thing existed.
This suggests the following idea. Given a subset ![A \subseteq \mathbb{N}]() , we look at its measure under the zeta distribution
, we look at its measure under the zeta distribution
![\displaystyle \mu_s(A) = \frac{1}{\zeta(s)} \left( \sum_{a \in A} \frac{1}{a^s} \right)]()
and then we take the high-temperature limit ![s \to 1^{+}]() . The resulting number, when it exists, turns out to equal the logarithmic density
. The resulting number, when it exists, turns out to equal the logarithmic density
![\displaystyle \mu_1(A) = \lim_{n \to \infty} \frac{ \sum_{a \in A, a \le n} \frac{1}{a} }{\ln n}]()
of ![A]() . The logarithmic density is still not a measure on
. The logarithmic density is still not a measure on ![\mathbb{N}]() , but it has the benefit of existing for more sets than the natural density. Even better, if a set
, but it has the benefit of existing for more sets than the natural density. Even better, if a set ![A]() has a natural density, then it also has a logarithmic density, and the two agree. So studying zeta distributions can tell us what the natural density of a subset
has a natural density, then it also has a logarithmic density, and the two agree. So studying zeta distributions can tell us what the natural density of a subset ![A]() has to be, if it exists.
has to be, if it exists.
The proof
One reason I was finally inspired to write this post is that the zeta distribution occurred on my measure theory homework. We were asked to prove that the events of being divisible by distinct primes were independent and that this implies the celebrated Euler product formula; note that this is already implicit in the above derivation, where the assumption of independence leads inevitably to the product formula. Then we were asked to prove that the probability that a positive integer is squarefree is equal to ![\frac{1}{\zeta(2s)}]() . But since a squarefree positive integer is just a product of distinct primes, this is just
. But since a squarefree positive integer is just a product of distinct primes, this is just
![\displaystyle \frac{1}{\zeta(s)} \prod_p \left( 1 + \frac{1}{p^s} \right) = \frac{1}{\zeta(s)} \prod_p \left( \frac{1 - \frac{1}{p^{2s}} }{1 - \frac{1}{p^s}} \right) = \frac{1}{\zeta(2s)}]()
as desired. Finally, we were asked to prove that the probability that two positive integers are relatively prime is also equal to ![\frac{1}{\zeta(2s)}]() . This can be done as follows: the probability that a positive integer is squarefree is the same as the probability that one positive integer
. This can be done as follows: the probability that a positive integer is squarefree is the same as the probability that one positive integer ![x]() is squarefree and another positive integer
is squarefree and another positive integer ![y]() is arbitrary. We want to show that this is the same as the probability that two positive integers
is arbitrary. We want to show that this is the same as the probability that two positive integers ![a, b]() are relatively prime. One way to show this is to exhibit a probability-preserving bijection between the two sets, which can be done as follows: given
are relatively prime. One way to show this is to exhibit a probability-preserving bijection between the two sets, which can be done as follows: given ![x]() squarefree and
squarefree and ![y]() arbitrary, send
arbitrary, send
![\displaystyle (x, y) \mapsto \left( x \gcd(x, y), \frac{y}{\gcd(x, y)} \right)]() .
.
This map is injective because ![x]() can be recovered as the radical of
can be recovered as the radical of ![x \gcd(x, y)]() . This map sends a squarefree positive integer and an arbitrary positive integer to two relatively prime positive integers, and it preserves probabilities. In the other direction, given
. This map sends a squarefree positive integer and an arbitrary positive integer to two relatively prime positive integers, and it preserves probabilities. In the other direction, given ![a, b]() relatively prime, let
relatively prime, let ![\text{rad}(n)]() denote the product of the primes dividing
denote the product of the primes dividing ![n]() and send
and send
![\displaystyle (a, b) \mapsto \left( \text{rad}(a), \frac{ab}{\text{rad}(a)} \right).]()
This gives a squarefree positive integer and another positive integer, and it preserves probabilities. In addition, it is not hard to verify that the two maps given above are inverses of each other.
This argument is equivalent to the statement that the number of ways to write a positive integer ![n]() as the product of two relatively prime positive integers is the same as the number of ways to write a positive integer
as the product of two relatively prime positive integers is the same as the number of ways to write a positive integer ![n]() as the product of a squarefree integer and an arbitrary integer, which is in turn equivalent to a Dirichlet series argument which computes the probabilities above directly. This number is a multiplicative function in
as the product of a squarefree integer and an arbitrary integer, which is in turn equivalent to a Dirichlet series argument which computes the probabilities above directly. This number is a multiplicative function in ![n]() , so it’s enough to verify that the two are equal for prime powers, which is clear. But I thought the above argument was cute.
, so it’s enough to verify that the two are equal for prime powers, which is clear. But I thought the above argument was cute.
In any case, it now follows that the “logarithmic probability” that two positive integers are relatively prime is ![\frac{1}{\zeta(2)}]() . Hence the “natural probability” that two positive integers are relatively prime, if it exists, is also
. Hence the “natural probability” that two positive integers are relatively prime, if it exists, is also ![\frac{1}{\zeta(2)}]() . So the mysterious appearance of the zeta function in this result is now hopefully not so mysterious.
. So the mysterious appearance of the zeta function in this result is now hopefully not so mysterious.
Generalizations
The above argument also works on more general zeta functions. For example, let ![R]() be a Dedekind domain such that, for every ideal
be a Dedekind domain such that, for every ideal ![I]() , the quotient
, the quotient ![R/I]() is finite; this is what Pete Clark calls a Dedekind abstract number ring, and it includes the ring of integers in any number field as well as the ring of integers in any finite extension of
is finite; this is what Pete Clark calls a Dedekind abstract number ring, and it includes the ring of integers in any number field as well as the ring of integers in any finite extension of ![\mathbb{F}_p(x)]() . Define the norm of an ideal
. Define the norm of an ideal ![I]() to be
to be ![N(I) = |R/I|]() . Then we can define the Dedekind zeta function
. Then we can define the Dedekind zeta function
![\displaystyle \zeta_R(s) = \sum_I \frac{1}{N(I)^s} = \prod_P \frac{1}{1 - N(P)^{-s}}]()
where the Euler product is taken over prime ideals. When ![R = \mathbb{Z}]() , this is just the Riemann zeta function. When
, this is just the Riemann zeta function. When ![R = \mathbb{F}_q[x]]() , every ideal is principal and generated by some polynomial
, every ideal is principal and generated by some polynomial ![f(x)]() , and the norm of the corresponding ideal is
, and the norm of the corresponding ideal is ![q^n]() where
where ![n = \deg f]() . Since there are exactly
. Since there are exactly ![q^n]() monic polynomials of degree
monic polynomials of degree ![n]() , it follows that
, it follows that
![\displaystyle \zeta_{\mathbb{F}_q[x]}(s) = \sum_{n \ge 0} q^n t^n = \frac{1}{1 - qt}]()
where ![t = q^{-s}]() . The corresponding Euler product is described in this previous post.
. The corresponding Euler product is described in this previous post.
The Dedekind zeta function of ![R]() describes, for fixed
describes, for fixed ![s]() such that the sum converges, a probability distribution on the set of ideals of
such that the sum converges, a probability distribution on the set of ideals of ![R]() , where the ideal
, where the ideal ![I]() occurs with probability
occurs with probability ![\frac{1}{\zeta_R(s)} \left( \frac{1}{N(I)^s} \right)]() . Since ideals uniquely factor into products of prime ideals, everything that was said above carries over verbatim to any
. Since ideals uniquely factor into products of prime ideals, everything that was said above carries over verbatim to any ![R]() . (In statistical-mechanical language, the prime ideals are the “primons” out of which states are built, and a prime ideal
. (In statistical-mechanical language, the prime ideals are the “primons” out of which states are built, and a prime ideal ![P]() has energy
has energy ![\log N(P)]() .) This implies, for example, that in the limit as
.) This implies, for example, that in the limit as ![s \to 1^{+}]() , the probability that a polynomial in
, the probability that a polynomial in ![\mathbb{F}_q[x]]() is squarefree, which is also equal to the probability that two polynomials in
is squarefree, which is also equal to the probability that two polynomials in ![\mathbb{F}_q[x]]() are relatively prime, equals
are relatively prime, equals
![\displaystyle \frac{1}{\zeta_{\mathbb{F}_q[x]}(2)} = 1 - \frac{1}{q}]() .
.
There is a beautiful blog post by Jordan Ellenberg which explains how to get the analogous version of this statement when ![\mathbb{F}_q]() is replaced by
is replaced by ![\mathbb{C}]() .
.
What we have now is pretty funny: it is a probabilistic algorithm to compute ![\zeta_R(2)]() for any
for any ![R]() for which it is possible to explicitly construct random(ish) elements. In fact, if “squarefree” is replaced by “
for which it is possible to explicitly construct random(ish) elements. In fact, if “squarefree” is replaced by “![k]() -power free” for some
-power free” for some ![k]() then we have a probabilistic algorithm to compute
then we have a probabilistic algorithm to compute ![\zeta_R(k)]() for any positive integer
for any positive integer ![k]() . One might imagine an alien civilization discovering zeta functions this way.
. One might imagine an alien civilization discovering zeta functions this way.
In this generality, the construction of the profinite completion of ![R]() still makes sense, although it should be taken as a ring instead of just a group, where we take the limit over all finite quotient rings
still makes sense, although it should be taken as a ring instead of just a group, where we take the limit over all finite quotient rings ![R/I]() . It is closely related to the adele ring of
. It is closely related to the adele ring of ![R]() when
when ![R]() is the ring of integers in a finite extension of a global field, and its Haar measure is very important in the modern approach to algebraic number theory, beginning with Tate’s thesis. I’m not qualified to describe how this works in any more detail than that, unfortunately.
is the ring of integers in a finite extension of a global field, and its Haar measure is very important in the modern approach to algebraic number theory, beginning with Tate’s thesis. I’m not qualified to describe how this works in any more detail than that, unfortunately.
This whole discussion generalizes even further to dynamical zeta functions, although I’m not entirely sure what to make of it. It gives a probability distribution on the space of multisets of orbits in a dynamical system whose primons are the orbits, and where the energy of an orbit is the number of points it contains.
Energy
Recall that if ![Z(\beta)]() is the partition function of a statistical-mechanical system, then the negative logarithmic derivative
is the partition function of a statistical-mechanical system, then the negative logarithmic derivative
![\displaystyle - \frac{Z'(\beta)}{Z(\beta)} = - \frac{d}{d \beta} \log Z(\beta)]()
describes the average or expected energy of the system. For the Riemann zeta function, this gives
![\displaystyle - \frac{\zeta'(s)}{\zeta(s)} = - \frac{d}{ds} \log \zeta(s) = \sum_p \frac{p^{-s} \log p}{1 - p^{-s}}]() .
.
which is the Dirichlet series of the von Mangoldt function, and which figures in some proofs of the prime number theorem. Intuitively, this sum describes the contribution to the average energy of the system from each type of “primon” in the Riemann gas; the expected contribution to the energy from primon ![p]() is
is ![\log p]() times the expected number of
times the expected number of ![p]() -primons. One way to see why this expected number should be equal to
-primons. One way to see why this expected number should be equal to ![\frac{p^{-s}}{1 - p^{-s}}]() is to use the identity
is to use the identity
![\displaystyle \mathbb{E}(X) = \sum_{n \ge 1} \mathbb{P}(X \ge n)]()
which is valid for any non-negative integer-valued random variable ![X]() . (Note that one can run this argument in reverse to deduce the form of the Riemann zeta function from the average energy function; in particular, the Euler product is now a consequence of linearity of expectation!)
. (Note that one can run this argument in reverse to deduce the form of the Riemann zeta function from the average energy function; in particular, the Euler product is now a consequence of linearity of expectation!)
Now let ![(D, f)]() be a dynamical system; that is, let
be a dynamical system; that is, let ![D]() be a set and
be a set and ![f : D \to D]() a function. We require, as before, that for every
a function. We require, as before, that for every ![n]() the number
the number ![\text{Fix}(f^n)]() of fixed points of
of fixed points of ![f^n]() is finite. Then the energy corresponding to the dynamical zeta function
is finite. Then the energy corresponding to the dynamical zeta function
![\displaystyle \zeta_D(\beta) = \exp \left( \sum_{n \ge 1} (\text{Fix}(f^n)) \frac{e^{-\beta n}}{n} \right) = \prod_P \frac{1}{1 - e^{- \beta |P|}}]() ,
,
where the product runs over all orbits of ![f]() and
and ![|P|]() is the size of an orbit, is equal to
is the size of an orbit, is equal to
![\displaystyle - \frac{d}{d \beta} \log \zeta_D(\beta) = \sum_{n \ge 1} \text{Fix}(f^n) e^{-\beta n} = \sum_P \frac{|P| e^{-\beta |P|}}{1 - e^{-\beta |P|}}]() .
.
The RHS follows from our computation of the average energy by summing over the average contribution from each primon, and the LHS is equal to the RHS because any element of ![\text{Fix}(f^n)]() corresponds to some number of copies of the same orbit (that is, primon). This is, to me, an appealing way to think about the equivalence between the exponential and product forms of the dynamical zeta function. Previously I only had a purely combinatorial way of thinking about it, but the energy computation is a nice alternate perspective, especially as it applies to the case where
corresponds to some number of copies of the same orbit (that is, primon). This is, to me, an appealing way to think about the equivalence between the exponential and product forms of the dynamical zeta function. Previously I only had a purely combinatorial way of thinking about it, but the energy computation is a nice alternate perspective, especially as it applies to the case where ![X]() is a variety over
is a variety over ![\overline{\mathbb{F}_q}]() and
and ![f]() is the Frobenius map.
is the Frobenius map.




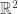




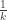








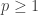






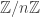












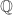


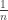


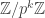

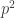



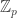

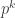
























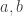











![R = \mathbb{F}_q[x]](http://s0.wp.com/latex.php?latex=R+%3D+%5Cmathbb%7BF%7D_q%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)



![\displaystyle \zeta_{\mathbb{F}_q[x]}(s) = \sum_{n \ge 0} q^n t^n = \frac{1}{1 - qt}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Czeta_%7B%5Cmathbb%7BF%7D_q%5Bx%5D%7D%28s%29+%3D+%5Csum_%7Bn+%5Cge+0%7D+q%5En+t%5En+%3D+%5Cfrac%7B1%7D%7B1+-+qt%7D&bg=ffffff&fg=333333&s=0&c=20201002)




![\mathbb{F}_q[x]](http://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_q%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle \frac{1}{\zeta_{\mathbb{F}_q[x]}(2)} = 1 - \frac{1}{q}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7B%5Czeta_%7B%5Cmathbb%7BF%7D_q%5Bx%5D%7D%282%29%7D+%3D+1+-+%5Cfrac%7B1%7D%7Bq%7D&bg=ffffff&fg=333333&s=0&c=20201002)