I finally learned the solution to a little puzzle that’s been bothering me for awhile.
The setup of the puzzle is as follows. Let ![G]() be a weighted undirected graph, e.g. to each edge
be a weighted undirected graph, e.g. to each edge ![i \leftrightarrow j]() is associated a non-negative real number
is associated a non-negative real number ![a_{ij}]() , and let
, and let ![A]() be the corresponding weighted adjacency matrix. If
be the corresponding weighted adjacency matrix. If ![A]() is stochastic, one can interpret the weights
is stochastic, one can interpret the weights ![a_{ij}]() as transition probabilities between the vertices which describe a Markov chain. (The undirected condition then means that the transition probability between two states doesn’t depend on the order in which the transition occurs.) So one can talk about random walks on such a graph, and between any two vertices the most likely walk is the one which maximizes the product of the weights of the corresponding edges.
as transition probabilities between the vertices which describe a Markov chain. (The undirected condition then means that the transition probability between two states doesn’t depend on the order in which the transition occurs.) So one can talk about random walks on such a graph, and between any two vertices the most likely walk is the one which maximizes the product of the weights of the corresponding edges.
Suppose you don’t want to maximize a product associated to the edges, but a sum. For example, if the vertices of ![G]() are locations to which you want to travel, then maybe you want the most likely random walk to also be the shortest one. If
are locations to which you want to travel, then maybe you want the most likely random walk to also be the shortest one. If ![E_{ij}]() is the distance between vertex
is the distance between vertex ![i]() and vertex
and vertex ![j]() , then a natural way to do this is to set
, then a natural way to do this is to set
![a_{ij} = e^{- \beta E_{ij}}]()
where ![\beta]() is some positive constant. Then the weight of a path is a monotonically decreasing function of its total length, and (fudging the stochastic constraint a bit) the most likely path between two vertices, at least if
is some positive constant. Then the weight of a path is a monotonically decreasing function of its total length, and (fudging the stochastic constraint a bit) the most likely path between two vertices, at least if ![\beta]() is sufficiently large, is going to be the shortest one. In fact, the larger
is sufficiently large, is going to be the shortest one. In fact, the larger ![\beta]() is, the more likely you are to always be on the shortest path, since the contribution from any longer paths becomes vanishingly small. As
is, the more likely you are to always be on the shortest path, since the contribution from any longer paths becomes vanishingly small. As ![\beta \to \infty]() , the ring in which the entries of the adjacency matrix lives stops being
, the ring in which the entries of the adjacency matrix lives stops being ![\mathbb{R}]() and becomes (a version of) the tropical semiring.
and becomes (a version of) the tropical semiring.
That’s pretty cool, but it’s not what’s been puzzling me. What’s been puzzling me is that matrix entries in powers of ![A]() look an awful lot like partition functions in statistical mechanics, with
look an awful lot like partition functions in statistical mechanics, with ![\beta]() playing the role of the inverse temperature and
playing the role of the inverse temperature and ![E_{ij}]() playing the role of energies. So, for awhile now, I’ve been wondering whether they actually are partition functions of systems I can construct starting from the matrix
playing the role of energies. So, for awhile now, I’ve been wondering whether they actually are partition functions of systems I can construct starting from the matrix ![A]() . It turns out that the answer is yes: the corresponding systems are called one-dimensional vertex models, and in the literature the connection to matrix entries is called the transfer matrix method. I learned this from an expository article by Vaughan Jones, “In and around the origin of quantum groups,” and today I’d like to briefly explain how it works.
. It turns out that the answer is yes: the corresponding systems are called one-dimensional vertex models, and in the literature the connection to matrix entries is called the transfer matrix method. I learned this from an expository article by Vaughan Jones, “In and around the origin of quantum groups,” and today I’d like to briefly explain how it works.
Partition functions
Suppose the states of a system form a (preferably finite) set ![S]() . Each state has some energy
. Each state has some energy ![E_s, s \in S]() , and in the typical setup in statistical mechanics, the system is constantly changing state in such a way that the probability of a given state occurring depends only on the energy. Furthermore, essentially the only other thing we know about the system is its average energy
, and in the typical setup in statistical mechanics, the system is constantly changing state in such a way that the probability of a given state occurring depends only on the energy. Furthermore, essentially the only other thing we know about the system is its average energy
![\displaystyle \sum_{s \in S} p_s E_s]()
where ![p_s]() is the probability of state
is the probability of state ![s]() occurring. (This average is determined by the behavior of a large external system, which, as it turns out, can be described entirely by its temperature.) Without knowing anything else about the system, what is a sensible choice for the probabilities
occurring. (This average is determined by the behavior of a large external system, which, as it turns out, can be described entirely by its temperature.) Without knowing anything else about the system, what is a sensible choice for the probabilities ![p_s]() ? The key is to choose a distribution which maximizes entropy. This corresponds to a distribution which does not reflect any “extra” knowledge about the system.
? The key is to choose a distribution which maximizes entropy. This corresponds to a distribution which does not reflect any “extra” knowledge about the system.
Theorem: There exists a constant ![\beta]() which depends on the average energy such that the distribution
which depends on the average energy such that the distribution ![\displaystyle p_s = \frac{1}{Z} e^{-\beta E_s}]() is entropy maximal, where
is entropy maximal, where ![\displaystyle Z = \sum_{s \in S} e^{-\beta E_s}]() is the partition function.
is the partition function.
This is beautifully explained in this expository note by Keith Conrad. Terence Tao also describes the more typical physically-motivated route to this distribution, but I can’t resist any definition that has an accompanying uniqueness statement.
(I also can’t resist mentioning that many important functions in pure mathematics can be thought of as partition functions. For example, the system whose states are the positive integers and whose energies are ![E_n = \log n]() has partition function the Riemann zeta function! This system is known as the primon gas or free Riemann gas. It is also possible to write down some knot invariants as partition functions.)
has partition function the Riemann zeta function! This system is known as the primon gas or free Riemann gas. It is also possible to write down some knot invariants as partition functions.)
By comparison to an ideal gas, we find that ![\beta = \frac{1}{kT}]() where
where ![k]() is the Boltzmann constant and
is the Boltzmann constant and ![T]() is the temperature of the large external system, with which the system
is the temperature of the large external system, with which the system ![S]() must be in thermal equilibrium for these equations to be valid. This is physically sensible: as
must be in thermal equilibrium for these equations to be valid. This is physically sensible: as ![T \to \infty, e^{-\beta E_s} \to 1]() and every state is equally likely. Similarly, as
and every state is equally likely. Similarly, as ![T \to 0, \beta \to \infty]() and the state(s) of minimal energy become asymptotically more and more likely.
and the state(s) of minimal energy become asymptotically more and more likely.
Note that the average energy of the system is ![- \frac{Z'(\beta)}{Z(\beta)} = - \frac{d}{d\beta} \log Z]() , which really is determined by
, which really is determined by ![\beta]() . In fact, one can compute the moments of the distribution of energies from the partition function, so the partition function encodes essentially all of the important information about the system.
. In fact, one can compute the moments of the distribution of energies from the partition function, so the partition function encodes essentially all of the important information about the system.
One-dimensional vertex models
We want to consider (finite approximations to) the following system. A state of the system consists of an assignment of a “spin” to each edge in the graph with vertex set ![\mathbb{Z}]() and edges between two consecutive integers. A spin is a vertex of a finite weighted undirected graph
and edges between two consecutive integers. A spin is a vertex of a finite weighted undirected graph ![G]() , and the interaction between two spins is measured by an energy
, and the interaction between two spins is measured by an energy ![E_{ij}]() which determines the weight
which determines the weight ![a_{ij} = e^{- \beta E_{ij}}]() of the edge from
of the edge from ![i]() to
to ![j]() at a particular temperature. The motivating example here is the Ising model, which is a simplified model of the spins of electrons in iron, and which models ferromagnetism. (In one dimension, it doesn’t matter whether we assign spins to the edges or to the vertices, but it matters in higher dimensions. This type of model is called a vertex model because the interactions occur at the vertices.) If the spins assigned to each edge are
at a particular temperature. The motivating example here is the Ising model, which is a simplified model of the spins of electrons in iron, and which models ferromagnetism. (In one dimension, it doesn’t matter whether we assign spins to the edges or to the vertices, but it matters in higher dimensions. This type of model is called a vertex model because the interactions occur at the vertices.) If the spins assigned to each edge are ![... v(-2), v(-1), v(0), v(1), v(2), ...]() then the energy of a particular state is the sum of the interaction energies between consecutive spins, or
then the energy of a particular state is the sum of the interaction energies between consecutive spins, or
![\displaystyle \sum_{k \in \mathbb{Z}} E_{v(k) v(k+1)}]()
so the partition function is
![\displaystyle \sum_v \prod_{k \in \mathbb{Z}} e^{- \beta E_{v(k) v(k+1)} }]()
where the outer sum is over all possible assignments of spins to edges. Since we don’t want to deal with infinite sums directly, we’ll instead consider a finite approximation to the above system in which there are ![N]() edges to assign spins to and take the limit as
edges to assign spins to and take the limit as ![N \to \infty]() .
.
The key observation here is that states in the ![N]() -edge model are the same as walks of length
-edge model are the same as walks of length ![N-1]() on the graph
on the graph ![G]() , with the probability of each state occurring proportional to the product of the weights of the edges (of the walk, not of the model). Thus, for example, if we specify boundary conditions saying that the first spin should be
, with the probability of each state occurring proportional to the product of the weights of the edges (of the walk, not of the model). Thus, for example, if we specify boundary conditions saying that the first spin should be ![i]() and the last spin should be
and the last spin should be ![j]() , then the partition function of the corresponding system is
, then the partition function of the corresponding system is ![Z_N = A_{ij}^{N-1}]() , where
, where ![A]() is the matrix with entries
is the matrix with entries ![e^{- \beta E_{ij}}]() . And if we specify periodic boundary conditions saying that the first spin and the last spin should agree, then the partition function of the corresponding system is
. And if we specify periodic boundary conditions saying that the first spin and the last spin should agree, then the partition function of the corresponding system is ![Z_N = \text{tr } A^{N-1}]() . So these are the systems we want!
. So these are the systems we want!
Now that we know something about the finite approximations to a one-dimensional vertex model, what can we say about the actual model? That is, what does the limit as ![N \to \infty]() look like? One way to think about this limit is to measure the average energy per edge (say with periodic boundary conditions), so we want to compute
look like? One way to think about this limit is to measure the average energy per edge (say with periodic boundary conditions), so we want to compute
![\displaystyle \lim_{N \to \infty} \frac{- \frac{d}{d \beta} \log Z_N }{N}]() .
.
Since ![A]() is a matrix with positive real entries, the Perron-Frobenius theorem guarantees that for any particular value of
is a matrix with positive real entries, the Perron-Frobenius theorem guarantees that for any particular value of ![\beta]() there is a unique positive real eigenvalue of largest absolute value, so in the limit
there is a unique positive real eigenvalue of largest absolute value, so in the limit ![\log Z_N \sim (N-1) \log \lambda]() where
where ![\lambda]() is this eigenvalue. It is not hard to see that
is this eigenvalue. It is not hard to see that ![\lambda]() must also change smoothly with
must also change smoothly with ![\beta]() , so the average energy per edge approaches
, so the average energy per edge approaches
![- \frac{d}{d \beta} \log \lambda]() .
.
The fact that this average energy (indeed, the higher moments of the energy distribution as well) changes smoothly with ![\beta]() implies that phase transitions do not occur in the one-dimensional vertex model. One must pass to the two-dimensional case for phase transitions to occur, and I would like to say something about this computation as soon as I can find a good source for it.
implies that phase transitions do not occur in the one-dimensional vertex model. One must pass to the two-dimensional case for phase transitions to occur, and I would like to say something about this computation as soon as I can find a good source for it.
Example. In the one-dimensional Ising model, ![G]() has two vertices, spin up and spin down. The energies are given by
has two vertices, spin up and spin down. The energies are given by ![E_{11} = E_{22} = -1]() and
and ![E_{12} = 1]() ; in other words, it is energetically favorable for spins to align and unfavorable for spins not to align. (This agrees with the experimental behavior of magnets: at low temperatures, their spins align and so they are magnetic, while at sufficiently high temperatures they demagnetize.) This gives
; in other words, it is energetically favorable for spins to align and unfavorable for spins not to align. (This agrees with the experimental behavior of magnets: at low temperatures, their spins align and so they are magnetic, while at sufficiently high temperatures they demagnetize.) This gives
![A = \left[ \begin{array}{cc} e^{\beta} & e^{-\beta} \\ e^{-\beta} & e^{\beta} \end{array} \right]]() .
.
The Perron-Frobenius eigenvalue of ![A]() is the larger of the two roots of its characteristic polynomial
is the larger of the two roots of its characteristic polynomial ![x^2 - 2 e^{-\beta} x + (e^{-2\beta} - e^{2\beta})]() , which is
, which is
![\lambda = e^{-\beta} + e^{\beta}]()
and hence the average energy per edge is given by
![\displaystyle - \frac{d}{d\beta} \log \lambda = - \frac{e^{\beta} - e^{-\beta}}{e^{\beta} + e^{-\beta}} = - \text{tanh } \beta]() .
.
At low temperatures, where ![\beta]() is large, the average energy per edge approaches
is large, the average energy per edge approaches ![-1]() ; almost complete alignment. At high temperatures, where
; almost complete alignment. At high temperatures, where ![\beta]() is small, the average energy approaches
is small, the average energy approaches ![0]() ; random alignment.
; random alignment.




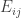



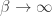





















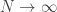
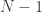









![A = \left[ \begin{array}{cc} e^{\beta} & e^{-\beta} \\ e^{-\beta} & e^{\beta} \end{array} \right]](http://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+e%5E%7B%5Cbeta%7D+%26+e%5E%7B-%5Cbeta%7D+%5C%5C+e%5E%7B-%5Cbeta%7D+%26+e%5E%7B%5Cbeta%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)




