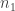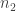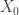The principle of maximum entropy asserts that when trying to determine an unknown probability distribution (for example, the distribution of possible results that occur when you toss a possibly unfair die), you should pick the distribution with maximum entropy consistent with your knowledge.
The goal of this post is to derive the principle of maximum entropy in the special case of probability distributions over finite sets from
We’ll do this by deriving an arguably more fundamental principle of maximum relative entropy using only Bayes’ theorem.
A better way to state Bayes’ theorem
Suppose you have a set ![I]() of hypotheses about something, exactly one of which can be true, and some prior probabilities
of hypotheses about something, exactly one of which can be true, and some prior probabilities ![\mathbb{P}(i), i \in I]() that these hypotheses are true (which therefore sum to
that these hypotheses are true (which therefore sum to ![1]() ). Then you see some evidence
). Then you see some evidence ![E]() . (Here is a simultaneous definition of both hypotheses and evidence: hypotheses are things that assert how likely or unlikely evidence is. That is, what it means to give evidence about some hypotheses is that there ought to be some conditional probabilities
. (Here is a simultaneous definition of both hypotheses and evidence: hypotheses are things that assert how likely or unlikely evidence is. That is, what it means to give evidence about some hypotheses is that there ought to be some conditional probabilities ![\mathbb{P}(E | i)]() , the likelihoods, describing how likely it is that you see evidence
, the likelihoods, describing how likely it is that you see evidence ![E]() conditional on hypothesis
conditional on hypothesis ![i]() .)
.)
Bayes’ theorem in this setting is then usually stated as follows: you should now have updated posterior probabilities ![\mathbb{P}(i | E)]() that your hypotheses are true conditional on your evidence, and they should be given by
that your hypotheses are true conditional on your evidence, and they should be given by
![\displaystyle \mathbb{P}(i | E) = \frac{\mathbb{P}(i) \mathbb{P}(E | i)}{\mathbb{P}(E)}]() .
.
That is, each prior probability ![\mathbb{P}(i)]() gets multiplied by
gets multiplied by ![\frac{\mathbb{P}(E | i)}{\mathbb{P}(E)}]() , which describes how much more likely
, which describes how much more likely ![i]() thinks the evidence
thinks the evidence ![E]() is than before. You might be concerned that
is than before. You might be concerned that ![\mathbb{P}(E)]() requires the introduction of extra information, but in fact it must be given by
requires the introduction of extra information, but in fact it must be given by
![\displaystyle \mathbb{P}(E) = \sum_i \mathbb{P}(i) \mathbb{P}(E | i)]()
by conditioning on each ![i]() in turn, so it’s already determined by the priors and the likelihoods. (This is if the
in turn, so it’s already determined by the priors and the likelihoods. (This is if the ![i]() are parameterized by a discrete parameter
are parameterized by a discrete parameter ![i]() ; in general this sum should be replaced by an integral.)
; in general this sum should be replaced by an integral.)
In practice this statement of Bayes’ theorem seems to be annoyingly easy to forget, at least for me. Here is a better statement. The idea is to think of ![\mathbb{P}(E)]() as just a normalization constant. Hence the revised statement is
as just a normalization constant. Hence the revised statement is
![\displaystyle \mathbb{P}(i | E) \propto \mathbb{P}(i) \mathbb{P}(E | i)]() .
.
That is, the posterior probability is proportional to the prior probability times the likelihood, where the proportionality constant is uniquely determined by the requirement that the probabilities sum to ![1]() .
.
Intuitively: after seeing some evidence, your confidence in a hypothesis gets multiplied by how well the hypothesis predicted the evidence, then normalized. Now you can take your posteriors to be your new priors in preparation for seeing some more evidence. This is a Bayesian update.
Aside: measures up to scale and improper priors
This statement of Bayes’ theorem suggests a slight reformulation of what we mean by a probability measure: a probability measure is the same thing as a measure with nonzero total measure, up to scaling by positive reals. One reason to like this description is that it naturally incorporates improper priors, which correspond to prior probabilities ![\mathbb{P}(i)]() with possibly infinite total measure, up to scaling by positive reals. The point is that after a Bayesian update an improper prior may become proper again. For example, there’s an improper prior assigning measure
with possibly infinite total measure, up to scaling by positive reals. The point is that after a Bayesian update an improper prior may become proper again. For example, there’s an improper prior assigning measure ![1]() to every positive integer
to every positive integer ![n]() , which allows us to talk about hypotheses
, which allows us to talk about hypotheses ![n \in \mathbb{N}]() indexed by the positive integers and with a prior which makes all of them equally likely.
indexed by the positive integers and with a prior which makes all of them equally likely.
Improper priors may seem obviously bad because they don’t assign probabilities to things: in order to assign a probability you need to normalize by the total measure, which is infinite. However, with an improper prior it is still meaningful to make comparisons between probabilities: you can still meaningfully say that ![\mathbb{P}(i)]() is larger than
is larger than ![\mathbb{P}(j)]() , or exactly
, or exactly ![r]() times
times ![\mathbb{P}(j)]() , since this comparison is invariant under scaling by positive reals.
, since this comparison is invariant under scaling by positive reals.
There’s a somewhat philosophical argument that when performing Bayesian reasoning, only comparisons between probabilities are meaningful anyway: in order to know the probability, in the absolute sense, of something, you need to be absolutely sure you’ve written down every possible hypothesis ![i]() (in order to ensure that exactly one of them is true). If you leave out the true hypothesis, then you might end up being more and more sure of an arbitrarily bad hypothesis because the true hypothesis wasn’t included in your calculations. In other words, computing the normalization constant
(in order to ensure that exactly one of them is true). If you leave out the true hypothesis, then you might end up being more and more sure of an arbitrarily bad hypothesis because the true hypothesis wasn’t included in your calculations. In other words, computing the normalization constant ![\mathbb{P}(E)]() in the usual statement of Bayes’ theorem is “global” in that it requires information about all of the
in the usual statement of Bayes’ theorem is “global” in that it requires information about all of the ![i]() , but computing
, but computing ![\mathbb{P}(i) \mathbb{P}(E | i)]() is “local” in that it only involves one
is “local” in that it only involves one ![i]() at a time.
at a time.
(And it’s not enough just to have a few hypotheses and then a catch-all hypothesis called “everything else,” because “everything else” is not a hypothesis in the sense that it does not assign likelihoods ![\mathbb{P}(E | i)]() . A hypothesis has to make predictions.)
. A hypothesis has to make predictions.)
The setup
Back to maximum entropy. Imagine that you are repeatedly rolling an ![n]() -sided die, and you don’t know what the various weights on the die are: that is, you don’t know the true probabilities
-sided die, and you don’t know what the various weights on the die are: that is, you don’t know the true probabilities ![p_k]() that the
that the ![k^{th}]() face of the die will come up.
face of the die will come up.
However, you have some hypotheses about these probabilities. Your hypotheses ![t \in T]() are parameterized by a parameter
are parameterized by a parameter ![t]() , which for the sake of concreteness we’ll take to be a real number or a tuple of real numbers, but which could in principle be anything. Your hypotheses assign probability
, which for the sake of concreteness we’ll take to be a real number or a tuple of real numbers, but which could in principle be anything. Your hypotheses assign probability ![p_k(t)]() to the
to the ![k^{th}]() face coming up. You also have some prior over your hypotheses, which we’ll write as a probability density function
face coming up. You also have some prior over your hypotheses, which we’ll write as a probability density function ![f(t)]() . Hence
. Hence ![f(t) \ge 0]() and
and
![\displaystyle \int f(t) \, dt = 1]()
while the ![p_k(t)]() are normalized so that
are normalized so that
![\displaystyle \sum_k p_k(t) = 1]() .
.
Example. If ![n = 2]() , we might imagine that we’re flipping a coin, with
, we might imagine that we’re flipping a coin, with ![p_0]() the probability that we flip tails and
the probability that we flip tails and ![p_1]() the probability that we flip heads. Our hypotheses might take the form
the probability that we flip heads. Our hypotheses might take the form ![p_0(t) = t, p_1(t) = 1 - t]() where
where ![t \in [0, 1]]() , and our prior might be the uniform prior: each
, and our prior might be the uniform prior: each ![t]() is equally likely. Hence our probability density is
is equally likely. Hence our probability density is ![f(t) = 1]() .
.
Now suppose you roll the die ![N]() times. What happens to your beliefs under Bayesian updating in the limit
times. What happens to your beliefs under Bayesian updating in the limit ![N \to \infty]() ?
?
The principle of maximum relative entropy
Suppose you see the ![k^{th}]() face come up
face come up ![N q_k]() times (so the
times (so the ![q_k]() are nonnegative and
are nonnegative and ![\sum_k q_k = 1]() ; they described observed relative frequencies of the various faces coming up, and altogether describe the empirical probability distribution). Hypothesis
; they described observed relative frequencies of the various faces coming up, and altogether describe the empirical probability distribution). Hypothesis ![t]() predicts that this happens with probability
predicts that this happens with probability
![\displaystyle \mathbb{P}(q | t) = \frac{N!}{\prod_k (N q_k)!} \prod_k p_k(t)^{N q_k}]() .
.
Let’s see how this function behaves as ![N \to \infty]() . Taking the log, and using Stirling’s approximation in the form
. Taking the log, and using Stirling’s approximation in the form
![\log N! \approx N \log N - N]()
we get
![\displaystyle \log \frac{N!}{\prod_k (N q_k)!} \approx \left( N \log N - N \right) - \sum_k \left( N q_k \log N q_k - N q_k \right)]() .
.
Various terms cancel here due to the fact that ![\sum_k q_k = 1]() . At the end of the day we get
. At the end of the day we get
![\displaystyle \log \frac{N!}{\prod_k (N q_k)!} \approx - N \left( \sum_k q_k \log q_k \right) = N H(q)]() .
.
This is the first apperarance of the function ![H(q) = - \sum_k q_k \log q_k]() , the entropy of
, the entropy of ![q]() , regarded as a probability distribution over faces. This is perhaps the most concrete and least mysterious way of introducing entropy: it’s a concise way of summarizing the asymptotic behavior of the multinomial distribution as
, regarded as a probability distribution over faces. This is perhaps the most concrete and least mysterious way of introducing entropy: it’s a concise way of summarizing the asymptotic behavior of the multinomial distribution as ![N \to \infty]() . Already we see that the entropy being larger corresponds to the counts
. Already we see that the entropy being larger corresponds to the counts ![N q_k]() being more likely, in a very serious way.
being more likely, in a very serious way.
But there’s a second term in the likelihood, so let’s compute the logarithm of that too. This gives
![\displaystyle \log p_k(t)^{N q_k} = N \sum_k q_k \log p_k(t)]() .
.
Thus the logarithm of the likelihood, or log-likelihood, is
![\displaystyle \log \mathbb{P}(q | t) \approx N \left( \sum_k q_k \log \frac{p_k(t)}{q_k} \right)]() .
.
Now the function that appears is the negative of the Kullback-Leibler divergence. We’ll call it the relative entropy (although this term is sometimes used for the KL divergence, not its negative) and denote it somewhat arbitrarily by ![H(p(t) \to q)]() .
.
Altogether, the posterior density is now proportional to
![\displaystyle f(t | q) \propto f(t) \exp \left( N H(p(t) \to q) \right)]() .
.
From here it’s not hard to see that the posterior density is overwhelmingly concentrated at the hypotheses ![t]() that maximize relative entropy
that maximize relative entropy ![H(p(t) \to q)]() as
as ![N \to \infty]() , subject to the constraint that the prior density
, subject to the constraint that the prior density ![f(t)]() is positive. This is because all the other posterior densities are exponentially smaller in comparison, and as long as the prior density
is positive. This is because all the other posterior densities are exponentially smaller in comparison, and as long as the prior density ![f(t)]() is positive, it doesn’t matter what its exact value is because it too is exponentially small in comparison to the main exponential term.
is positive, it doesn’t matter what its exact value is because it too is exponentially small in comparison to the main exponential term.
This calculation suggests that we can interpret the relative entropy ![H(p(t) \to q)]() as a measure of how well the hypothesis
as a measure of how well the hypothesis ![p(t)]() fits the evidence
fits the evidence ![q]() : the larger this number is, the better the fit. (A more common way to describe relative entropy is as a measure of how well a hypothesis fits the “truth.” Here our model for being told that
: the larger this number is, the better the fit. (A more common way to describe relative entropy is as a measure of how well a hypothesis fits the “truth.” Here our model for being told that ![q]() is the “truth” is seeing it asymptotically as
is the “truth” is seeing it asymptotically as ![N \to \infty]() .)
.)
Let’s wrap that conclusion up into a theorem.
Theorem: With hypotheses as above, as ![N \to \infty]() , Bayesian updates converge towards believing the hypothesis
, Bayesian updates converge towards believing the hypothesis ![t]() that maximizes the relative entropy
that maximizes the relative entropy ![H(p(t) \to q)]() subject to the constraint that the prior density
subject to the constraint that the prior density ![f(t)]() is positive.
is positive.
Now, suppose the true probabilities are ![p_k]() . Then as
. Then as ![N \to \infty]() we expect, by the law of large numbers, that the observed frequencies
we expect, by the law of large numbers, that the observed frequencies ![q_k]() approach the true probabilities
approach the true probabilities ![p_k]() . If the true probabilities are among our hypotheses
. If the true probabilities are among our hypotheses ![p_k(t)]() , we would hope, and it seems intuitively clear, that we’ll converge towards believing the true hypothesis. This requires showing the following.
, we would hope, and it seems intuitively clear, that we’ll converge towards believing the true hypothesis. This requires showing the following.
Theorem: The relative entropy ![H(p \to q)]() is nonpositive, and for fixed
is nonpositive, and for fixed ![q]() , it takes its maximum value
, it takes its maximum value ![0]() iff
iff ![p = q]() .
.
Proof. This is more or less a computation with Lagrange multipliers. For fixed ![q]() , we want to maximize
, we want to maximize
![\displaystyle H(p \to q) = \sum q_k \log \frac{p_k}{q_k}]()
subject to the constraint ![\sum p_k = 1]() . This constraint means that at a critical point of
. This constraint means that at a critical point of ![H]() (whether a maximum, a minimum, or a saddle point), all of the partial derivatives
(whether a maximum, a minimum, or a saddle point), all of the partial derivatives ![\frac{\partial H}{\partial p_k}]() should be equal. (Intuitively, we have a “budget” of probability to spend to increase
should be equal. (Intuitively, we have a “budget” of probability to spend to increase ![H]() , and as we spend more probability on one
, and as we spend more probability on one ![p_k]() we necessarily must spend less probability on the others. The critical points are then the points where we can’t do any better by shifting our probability budget, meaning that the marginal value of each probability increase is equally good.)
we necessarily must spend less probability on the others. The critical points are then the points where we can’t do any better by shifting our probability budget, meaning that the marginal value of each probability increase is equally good.)
We compute that
![\displaystyle \frac{\partial H}{\partial p_k} = \frac{q_k}{p_k}]()
so setting all partial derivatives equal we conclude that ![p_k]() must be proportional to
must be proportional to ![q_k]() , and the additional constraint
, and the additional constraint ![\sum p_k = 1]() gives
gives ![p_k = q_k]() for all
for all ![k]() .
.
At this critical point ![H]() takes value
takes value ![H(p \to p) = 0]() . Now we need to show that this critical point is a maximum and not a minimum. Since it’s the unique critical point, it suffices to show that it’s a local maximum. So, consider a point
. Now we need to show that this critical point is a maximum and not a minimum. Since it’s the unique critical point, it suffices to show that it’s a local maximum. So, consider a point ![p_k = q_k + \epsilon_k]() in a small neighborhood of this critical point, where
in a small neighborhood of this critical point, where ![\sum \epsilon_k = 0]() . To second order, we have
. To second order, we have
![\displaystyle \log \frac{q_k + \epsilon_k}{q_k} = \frac{\epsilon_k}{q_k} - \frac{\epsilon_k^2}{2q_k^2} + O \left( \frac{\epsilon_k^3}{q_k^3} \right)^3]()
and hence
![\displaystyle H(p \to q) = \sum_k \left( \epsilon_k - \frac{\epsilon_k^2}{2q_k} \right) + O \left( \sum_k \left( \frac{\epsilon_k}{q_k} \right)^3 \right).]()
The linear term ![\sum_k \epsilon_k]() vanishes, and the quadratic term is negative definite as desired. (Strictly speaking we need to require that the
vanishes, and the quadratic term is negative definite as desired. (Strictly speaking we need to require that the ![q_k]() are all positive, but if any of them happen to be zero then the corresponding value of
are all positive, but if any of them happen to be zero then the corresponding value of ![k]() can be safely ignored anyway, since it won’t figure in any of our computations.)
can be safely ignored anyway, since it won’t figure in any of our computations.) ![\Box]()
Corollary: With hypotheses as above, as ![N \to \infty]() , if the true hypothesis is among the hypotheses with positive density, Bayesian updates converge towards believing it. False hypotheses are disbelieved at an exponential rate with base the exponential of the relative entropy.
, if the true hypothesis is among the hypotheses with positive density, Bayesian updates converge towards believing it. False hypotheses are disbelieved at an exponential rate with base the exponential of the relative entropy.
In other words, as ![N \to \infty]() , the Bayesian definition of probability converges to the frequentist definition of probability.
, the Bayesian definition of probability converges to the frequentist definition of probability.
Example. Let’s return to the ![n = 2]() example, where we’re flipping a coin with an unknown bias
example, where we’re flipping a coin with an unknown bias ![t \in [0, 1]]() , so that
, so that ![p_0(t) = t, p_1(t) = 1 - t]() are the probabilities of flipping heads and tails respectively given bias
are the probabilities of flipping heads and tails respectively given bias ![t]() , and our prior is uniform. Suppose that after
, and our prior is uniform. Suppose that after ![N]() trials we observe
trials we observe ![N s]() heads and
heads and ![N (1 - s)]() tails, where
tails, where ![s \in [0, 1]]() . Then
. Then
![\displaystyle f_{\text{post}}(t) \propto t^{Ns} (1 - t)^{N(1-s)}]() .
.
(We can drop the binomial coefficient because it’s the same for all values of ![t]() and so can be absorbed into our proportionality constant. We introduced it into the above computation because it becomes important later.)
and so can be absorbed into our proportionality constant. We introduced it into the above computation because it becomes important later.)
This computation can be used to deduce the rule of succession, which asserts that at this point you should assign probability ![\frac{Ns + 1}{N + 1}]() to heads coming up on the next coin flip. Note that as
to heads coming up on the next coin flip. Note that as ![N \to \infty]() this converges to
this converges to ![s]() .
.
The posterior density can be written as
![\displaystyle f_{\text{post}}(t) \propto \exp \left( N (s \log t + (1 - s) \log (1 - t)) \right)]()
which takes its maximum value when ![t = s]() by our results above, although in this case one-variable calculus suffices to prove this. Near this maximum value, Taylor expanding around
by our results above, although in this case one-variable calculus suffices to prove this. Near this maximum value, Taylor expanding around ![t]() shows that, for values of
shows that, for values of ![t]() sufficiently close to
sufficiently close to ![s]() , the posterior density is approximately a Gaussian centered at
, the posterior density is approximately a Gaussian centered at ![s]() with standard deviation
with standard deviation ![O \left( \frac{1}{\sqrt{N}} \right)]() . Hence in order to be confident that the true bias lies in an interval of size
. Hence in order to be confident that the true bias lies in an interval of size ![\epsilon]() with high probability we need to look at
with high probability we need to look at ![O \left( \frac{1}{\epsilon^2} \right)]() coin flips.
coin flips.
Maximum entropy
We were supposed to get a criterion in terms of maximizing entropy, not relative entropy. What happened to that?
Now instead of knowing the relative frequencies ![q_k]() , let’s assume that we only know that they satisfy some conditions. For example, for any function
, let’s assume that we only know that they satisfy some conditions. For example, for any function ![X : \{ 1, 2, \dots n \} \to V]() , where
, where ![V]() is a finite-dimensional real vector space, we might know the expected value
is a finite-dimensional real vector space, we might know the expected value
![\displaystyle \langle X \rangle = \sum_k X_k q_k \in V]()
of ![X]() with respect to the empirical probability distribution. In statistical mechanics a typical and important example is that we might know the average energy. We also might be observing a random walk, and while we don’t know how many steps the random walker took in a given direction (perhaps because they’re moving too fast for us to see), we might know where they ended up after
with respect to the empirical probability distribution. In statistical mechanics a typical and important example is that we might know the average energy. We also might be observing a random walk, and while we don’t know how many steps the random walker took in a given direction (perhaps because they’re moving too fast for us to see), we might know where they ended up after ![N]() steps, which tells us the average of all the steps the walker took.
steps, which tells us the average of all the steps the walker took.
(Strictly speaking, if we’re talking about the empirical distribution, where in particular each ![q_k]() is necessarily rational, it’s too much to ask that any particular condition be exactly satisfied. We’d be happy to see that it’s asymptotically satisfied as
is necessarily rational, it’s too much to ask that any particular condition be exactly satisfied. We’d be happy to see that it’s asymptotically satisfied as ![N \to \infty]() , from which we’re concluding that our conditions are exactly satisfied for the true probabilities
, from which we’re concluding that our conditions are exactly satisfied for the true probabilities ![p_k]() , or something like that. It seems there’s something subtle going on here and I am going to completely ignore it.)
, or something like that. It seems there’s something subtle going on here and I am going to completely ignore it.)
Knowing the expected values of some functions is equivalent to knowing that the empirical distribution ![q]() lies in some affine subspace of the probability simplex
lies in some affine subspace of the probability simplex
![\displaystyle \Delta^{n-1} = \{ q \in \mathbb{R}^n : q_k \ge 0, \sum q_k = 1 \}]() .
.
However, more complicated constraints are possible. For example, suppose that ![n = n_1 n_2]() and that we’re really rolling two independent dice with
and that we’re really rolling two independent dice with ![n_1]() and
and ![n_2]() sides, respectively, so that we can relabel the possible outcomes with pairs
sides, respectively, so that we can relabel the possible outcomes with pairs
![(k_1, k_2) \in \{ 1, 2, \dots n_1 \} \times \{ 1, 2, \dots n_2 \}]() .
.
Observing this is true means that, at least asymptotically as ![N \to \infty]() , we observe that we can write
, we observe that we can write ![q_{(k_1, k_2)} = r_{k_1} s_{k_2}]() , where
, where
![\displaystyle r_{k_1} = \sum_{k_2} q_{(k_1, k_2)}]()
is the empirical probability that the first die comes up ![k_1]() , and similarly
, and similarly
![\displaystyle s_{k_2} = \sum_{k_1} q_{(k_1, k_2)}]()
is the empirical probability that the second die comes up ![k_2]() . This is a nonlinear constraint: in fact it describes a collection of quadratic equations that the variables
. This is a nonlinear constraint: in fact it describes a collection of quadratic equations that the variables ![q_{(k_1, k_2)}]() must satisfy. Imposing these equations turns out to be equivalent to imposing the simpler homogeneous quadratic equations
must satisfy. Imposing these equations turns out to be equivalent to imposing the simpler homogeneous quadratic equations
![\displaystyle q_{k_1, k_2} q_{k_3, k_4} = q_{k_1, k_4} q_{k_3, k_2}]()
which we might recognize as the equations cutting out the image of the Segre embedding
![\displaystyle \mathbb{P}^{n_1 - 1} \times \mathbb{P}^{n_2 - 1} \to \mathbb{P}^{n_1 n_2 - 1}]() .
.
The idea is to think of the probability simplex ![\Delta^d]() as sitting inside projective space
as sitting inside projective space ![\mathbb{P}^d]() ; then the restriction of the Segre embedding to probability simplices produces a map
; then the restriction of the Segre embedding to probability simplices produces a map
![\displaystyle \Delta^{n_1 - 1} \times \Delta^{n_2 - 1} \to \Delta^{n_1 n_2 - 1}]()
describing how a probability distribution ![r_k]() over the first die and a probability distribution
over the first die and a probability distribution ![s_k]() over the second die gives rise to a joint probability distribution
over the second die gives rise to a joint probability distribution ![q_{(k_1, k_2)} = r_{k_1} s_{k_2}]() over both of them. More complicated variations of this example are considered in algebraic statistics.
over both of them. More complicated variations of this example are considered in algebraic statistics.
In any case, the game is that instead of knowing the empirical distribution we now only know some conditions it satisfies. Write the set of all distributions satisfying these conditions as ![E]() . What happens as
. What happens as ![N \to \infty]() ? Hypothesis
? Hypothesis ![t]() still predicts that empirical distribution
still predicts that empirical distribution ![q]() occurs with probability
occurs with probability
![\displaystyle \mathbb{P}(q | t) = \frac{N!}{\prod_k (N q_k)!} \prod_k p_k(t)^{N q_k}]()
and hence it predicts that we observe that our conditions are satisfied with probability
![\displaystyle \mathbb{P}(E | t) = \sum_{q \in E} \frac{N!}{\prod_k (N q_k)!} \prod_k p_k(t)^{N q_k}]()
(where ![E]() is shorthand for the event
is shorthand for the event ![q \in E]() ). Using our previous approximations, we can rewrite this as
). Using our previous approximations, we can rewrite this as
![\displaystyle \mathbb{P}(E | t) \approx \sum_{q \in E} \exp N H(p(t) \to q)]()
which gives posterior densities
![\displaystyle f_{\text{post}}(t) \propto f(t) \sum_{q \in E} \exp N H(p(t) \to q)]() .
.
As before, we find that the posterior densities are overwhelmingly concentrated at the hypotheses ![p(t)]() that maximize relative entropy
that maximize relative entropy ![H(p(t) \to q)]() as
as ![N \to \infty]() (again subject to the constraint that
(again subject to the constraint that ![f(t) > 0]() ), but where
), but where ![q]() is now allowed to run over all
is now allowed to run over all ![q \in E]() .
.
If our prior assigns nonzero density to every possible probability distribution in the probability simplex (for simple, we could take ![t]() to be parameterized by the points of the probability simplex,
to be parameterized by the points of the probability simplex, ![p(t)]() to be the probability distribution corresponding to the point
to be the probability distribution corresponding to the point ![t]() , and
, and ![f(t)]() to be a constant, suitably normalized), then we know that relative entropy takes its maximum value
to be a constant, suitably normalized), then we know that relative entropy takes its maximum value ![0]() when its two arguments are equal, so we can restrict our attention to the case that
when its two arguments are equal, so we can restrict our attention to the case that ![p(t) = q]() above, and we find that, asymptotically as
above, and we find that, asymptotically as ![N \to \infty]() , the posterior density is proportional to the prior density
, the posterior density is proportional to the prior density ![f(t)]() as long as
as long as ![p(t)]() satisfies the conditions, and
satisfies the conditions, and ![0]() otherwise.
otherwise.
This is unsurprising: we assumed that all we were told about the empirical distribution is that it satisfied some conditions, so the only change we make to our prior is that we condition on that.
We still haven’t gotten a characterization in terms of entropy, as opposed to relative entropy. This is where we are going to invoke the principle of indifference, which in this situation asserts that the prior we should have is the one concentrated entirely at the hypothesis
![\displaystyle p_k = \frac{1}{n}]()
that the die rolls are being generated uniformly at random. Note that this means the posterior is also concentrated entirely at this hypothesis!
We now predict empirical probability distribution ![q]() with probability distributed according to the multinomial distribution, namely
with probability distributed according to the multinomial distribution, namely
![\displaystyle \mathbb{P}(q) = \frac{1}{n^N} \frac{N!}{\prod_k (N q_k)!} \approx \frac{1}{n^N} \exp N H(q)]()
where ![\displaystyle \frac{1}{n^N}]() is now a normalization constant and can be ignored, and
is now a normalization constant and can be ignored, and ![H(q) = - \sum q_k \log q_k]() is the entropy, rather than the relative entropy. This comes from substituting the uniform distribution for
is the entropy, rather than the relative entropy. This comes from substituting the uniform distribution for ![p]() into the relative entropy
into the relative entropy ![H(p \to q)]() .
.
We now want to ask a slightly different question than before. Before we were asking what our beliefs were about the underlying “true” probabilities generating the die rolls. Now we’ve already fixed those beliefs, and we’re instead going to ask what our beliefs are about the empirical distribution ![q]() , which we now no longer know, conditioned on the fact that
, which we now no longer know, conditioned on the fact that ![q \in E]() . By Bayes’ theorem, this is
. By Bayes’ theorem, this is
![\displaystyle \mathbb{P}(q | E) \propto \mathbb{P}(q) \mathbb{P}(E | q)]()
where ![\mathbb{P}(E | q)]() is either
is either ![1]() if
if ![q \in E]() or
or ![0]() if
if ![q \not \in E]() , and
, and ![\mathbb{P}(q) \propto \exp N H(q)]() as before. Overall, we conclude the following.
as before. Overall, we conclude the following.
Theorem: Starting from the indifference prior, as ![N \to \infty]() Bayesian updates converge towards believing that the empirical distribution
Bayesian updates converge towards believing that the empirical distribution ![q]() is the maximum entropy distribution in
is the maximum entropy distribution in ![E]() .
.
In some sense this is not at all a deep statement: it’s just the observation that entropy describes the asymptotics of the multinomial distribution, together with conditioning on ![q \in E]() . Although it is somewhat interesting that conditioning on
. Although it is somewhat interesting that conditioning on ![q \in E]() , in this setup, is done by seeing that
, in this setup, is done by seeing that ![q]() appears to asymptotically lie in
appears to asymptotically lie in ![E]() as
as ![N \to \infty]() .
.
Edit: This is essentially the Wallis derivation, but with a much larger emphasis placed on the choice of prior.
Example. Suppose ![E]() consists of all probability distributions such that the expected value
consists of all probability distributions such that the expected value
![\langle X \rangle = \sum X_k q_k]()
of some random variable ![X : \{ 1, 2, \dots n \} \to V]() (possibly vector-valued) is fixed; call this fixed value
(possibly vector-valued) is fixed; call this fixed value ![X_0]() . Then we want to maximize
. Then we want to maximize ![H(q) = - \sum q_k \log q_k]() subject to this constraint and the constraint
subject to this constraint and the constraint ![\sum q_k = 1]() . This is again a Lagrange multiplier problem. We’ll introduce a vector-valued Lagrange multipler
. This is again a Lagrange multiplier problem. We’ll introduce a vector-valued Lagrange multipler ![\lambda \in V^{\ast}]() , as well as a scalar Lagrange multiplier
, as well as a scalar Lagrange multiplier ![r - 1]() for the constraint
for the constraint ![\sum q_k = 1]() that will later disappear from the calculation. (The
that will later disappear from the calculation. (The ![-1]() will slightly simplify the calculation.)
will slightly simplify the calculation.)
Then the method of Lagrange multipliers says that any maximum must be a critical point of the function
![\displaystyle L(q, \lambda) = \lambda \langle X \rangle + (r - 1) \left( \sum q_k \right) - H(q)]()
for some value of ![\lambda]() and
and ![r]() . (Here we are hiding the dependence of
. (Here we are hiding the dependence of ![\langle X \rangle]() on
on ![q]() .) Using the fact that
.) Using the fact that
![\displaystyle \frac{d}{dx} \left( -x \log x \right) = - \log x - 1]()
we compute that
![\displaystyle \frac{\partial L}{\partial q} = \lambda (X_k) + \log q_k + r]()
and setting these partial derivatives equal to ![0]() gives
gives
![\displaystyle q_k = e^{- \lambda (X_k) - r} = \frac{1}{Z} e^{-\lambda (X_k)}]()
where ![Z = e^r]() . But since the
. But since the ![q_k]() must sum to
must sum to ![1]() ,
, ![Z]() is a normalization constant determined by this condition, and in fact must be the partition function
is a normalization constant determined by this condition, and in fact must be the partition function
![\displaystyle Z = \sum_k e^{-\lambda (X_k)}]() .
.
From here we can compute that the expected value of ![X]() is
is
![\displaystyle \langle X \rangle = \frac{1}{Z} \sum_k X_k e^{-\lambda (X_k)} = - \frac{d \log Z}{d \lambda}]()
and the entropy is
![\displaystyle H = \langle -\log q \rangle = \log Z + \frac{1}{Z} \sum_k \lambda (X_k) e^{-\lambda (X_k)} = \log Z + \lambda \langle X \rangle]() .
.
In statistical mechanics, a “die” is a statistical-mechanical system, and ![X]() is a vector of variables such as energy and particle number describing that system.
is a vector of variables such as energy and particle number describing that system. ![\lambda]() , the Lagrange multiplier, is a vector of conjugate variables such as (inverse) temperature and chemical potential. The probability distribution
, the Lagrange multiplier, is a vector of conjugate variables such as (inverse) temperature and chemical potential. The probability distribution ![q]() we’ve just described is the canonical ensemble if
we’ve just described is the canonical ensemble if ![X]() consists only of energy and the grand canonical ensemble if
consists only of energy and the grand canonical ensemble if ![X]() consists of energy and particle numbers.
consists of energy and particle numbers.
The uniform prior we assumed using the principle of indifference, possibly after conditioning on a fixed value of the energy (rather than a fixed expected value), is the microcanonical ensemble. The assumption that this is a reasonable prior is called the fundamental postulate of statistical mechanics. As Terence Tao explains here, in a suitable finite toy model involving Markov chains at equilibrium it can be proven rigorously, but in more complicated settings the fundamental postulate is harder to justify, and of course in some settings it will just be wrong. In these settings we can instead use the principle of maximum relative entropy.
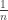 to each of
to each of 






















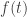




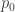
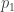

![t \in [0, 1]](http://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)


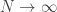













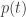



















![s \in [0, 1]](http://s0.wp.com/latex.php?latex=s+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)